On knot detection via picture recognition
A first step toward reading knot diagrams from images: machine perception first, rigorous invariants afterwards.
Data
- Title: On knot detection via picture recognition
- Authors: Anne Dranowski, Yura Kabkov and Daniel Tubbenhauer
- Status: preprint. Last update: Mon, 6 Oct 2025 22:36:10 UTC
- Code and (possibly empty) Erratum: Click
- ArXiv link: https://arxiv.org/abs/2510.06284
Abstract
Our goal is to one day take a photo of a knot and have a phone automatically recognize it. In this expository work, we explain a strategy to approximate this goal, using a mixture of modern machine learning methods (in particular convolutional neural networks and transformers for image recognition) and traditional algorithms (to compute quantum invariants like the Jones polynomial). We present simple baselines that predict crossing number directly from images, showing that even lightweight CNN and transformer architectures can recover meaningful structural information. The longer-term aim is to combine these perception modules with symbolic reconstruction into planar diagram (PD) codes, enabling downstream invariant computation for robust knot classification. This two-stage approach highlights the complementarity between machine learning, which handles noisy visual data, and invariants, which enforce rigorous topological distinctions.
What is the point?
The long-term dream is simple to say: take a picture of a knot and have a computer identify it. This paper starts with a controlled version of that problem, using image-recognition models to extract structural information from knot diagrams, with symbolic topology waiting downstream.
A picture of a knot diagram.
CNNs and transformers detect visible structure.
The eventual target is a PD code and invariant computation.
Talks and videos
A picture
Knots as visual objects, and why recognition from images matters.
A few extra words
Knot recognition, the process of describing the knot we are looking at, is surprisingly hard.
Knots, like cats, can be classified according to distinguishing attributes: just as a Siamese is distinct from a Persian, so is the unknot (an unknotted string) distinct from the trefoil.
The difficulty is that, unlike cats, we have little intuitive training data for knots, and diagrams of the same knot can vary wildly in appearance.
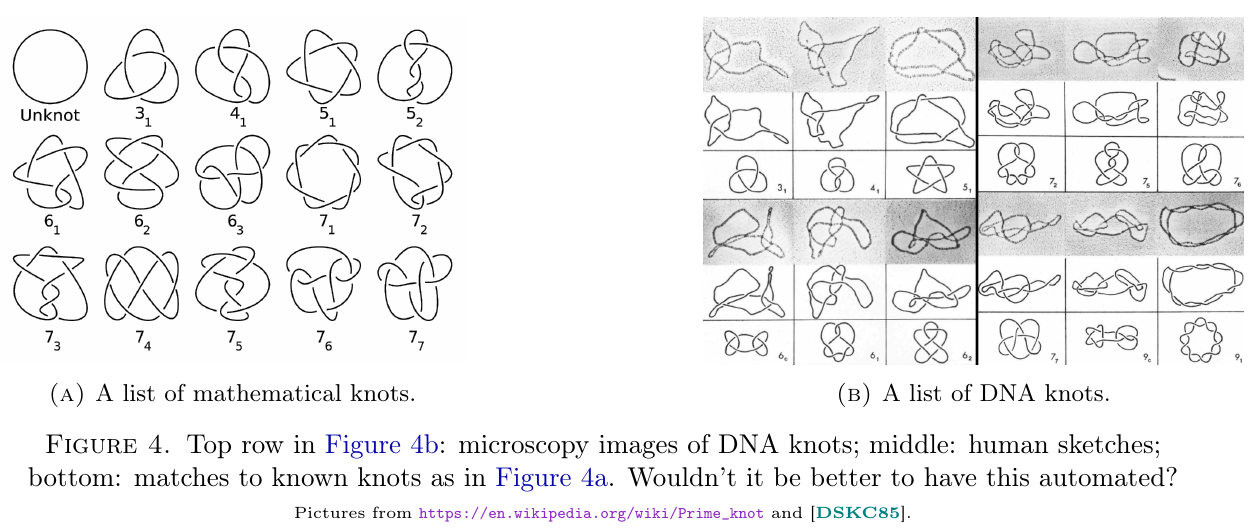
Why bother?
Knots are not just mathematical curiosities, they appear
in DNA topology, protein folding, polymer science, fluid dynamics, and beyond.
In these fields, identifying the knot from an image (for instance, from an electron microscope) is a common task.
At present this is often done by hand: drawing a diagram from the image, then matching it against known knot types.
This process is labor-intensive, error-prone, and strongly dependent on expert intuition. Automating it would improve speed, reproducibility, and accessibility.
Our long-term goal is to take a picture of a knot and have a computer tell us what it is: think about an app on your phone.
In this paper we take a tiny first step: predicting the number of crossings of a knot diagram directly from an image using convolutional neural networks (CNNs) and transformers.
Ultimately, we want the model to output a planar diagram (PD) presentation so that established algorithms can compute quantum invariants such as the Jones polynomial.
This two-stage approach balances the strengths of modern machine learning with the reliability of mathematical invariants.